Forzar cluster failover con CheckPoint
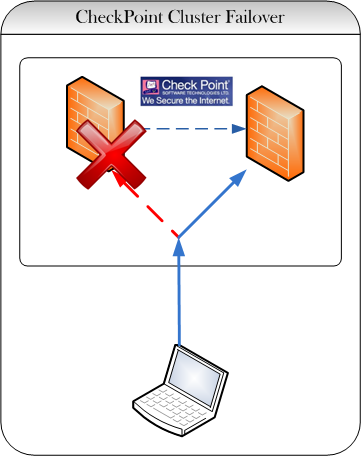 Esto es un pequeño truco para los adminsitradores de CheckPoint que tienen un cluster HA (Activo/Pasivo) y quieren forzar un failover manual para probar el funcionamiento del mismo.
Esto es un pequeño truco para los adminsitradores de CheckPoint que tienen un cluster HA (Activo/Pasivo) y quieren forzar un failover manual para probar el funcionamiento del mismo.
Hasta ahora, esta operativa la hacía haciendo un “cpstop” desde el CLI. Esto paraba todos los servicios de CheckPoint y forzaba el failover. Otra opción a la que recurría a veces es tirando un interfaz de red, poniendo el puerto del switch en shutdown. Por último, reiniciando el nodo, también se hacía failover.
Esas opciones son totalmente válidas y es interesante probarlas, pero la que os voy a detallar a continuación trabaja a nivel de comunicación de ClusterXL de CheckPoint. Lo que haremos es registrar un problema de cluster en el nodo activo, de forma que se produzca el failover de forma controlada.
Los comandos son los siguientes.
Registrar el fallo:
cphaprob -d fail -s problem -t 0 register
En este momento, se hace failover, se puede comprobar con el comando:
cphaprob stat
Cluster Mode: New High Availability (Active Up)
with IGMP Membership
Number Unique Address Assigned Load State
1 (local) 1.1.1.2 100% Active
2 1.1.1.3 0% Standby
Donde podemos ver quien es el nodo activo. Para quitar el fallo y dejarlo en OK. Los comandos a ejecutar serían:
cphaprob -d fail -s ok report
cphaprob -d fail unregister
Si tenemos puesto un Master preferido, se realizará el fallback. En caso contrario, seguirá activo el nodo actual.
Con estos sencillos comandos, podemos probar a forzar cluster failover con CheckPoint de forma controlada sin arriesgar a provocar otro problema, como reiniciando el firewall por ejemplo.